
Legal cases, patent registration, copyright issues, and progress are reasons why the ability to travel back in internet-time is essential. In 1996, Brewster Kahle and Bruce Gilliat (founders of Alexa, currently owned by Amazon) developed a program that would go on to set the stage for archiving web pages.
However, it was not until 2001 that the Wayback Machine was launched. The Wayback Machine is a digital archive of internet content. Since its inception in 2001, it has stored billions of snapshots of web pages in thousands of terabytes. This information is accessible on the internet six months after being archived.
You can do so by visiting their official site and pasting the URL to whichever page you want to travel in time. Let’s say you want to view Google history and search Wayback Machine Google.
The content stored in the Wayback Machine is collected using web-crawling or spidering software. This software derives and identifies domains from Alexa and follows a series of rules to retrieve and collect content. This is then captured and stored as web pages. It’s very easy to operate, and you can use Wayback machine search.
It does not record everything
The page’s robot.txt file defines the rules of spidering content on a web page. Some page domains allow crawling, others do not. In a case where the page domain does not permit, the Wayback machine records “no crawl” as its snapshot in its archives.
The content that is captured by the Wayback Machine is extracted from the server storage, usually HTML files. For this reason, the content captured is not as a user would see it on a browser.
Crawling may not capture all images, software codes, and other files. The Wayback machine captures web pages by following hyperlinks to other content in the same domain. Hyperlinks to other content in a different domain are not indexed.
Wayback Machine Alternatives
There are two types of Wayback Machine alternative sites similar in functionality to the Wayback Machine. The first type allows you to access past web pages like the Wayback Machine. They include an archive.is and screenshot.com, among others. The second alternative allows one to create a private “Wayback Machine” for specific purposes.
1. ScreenShots
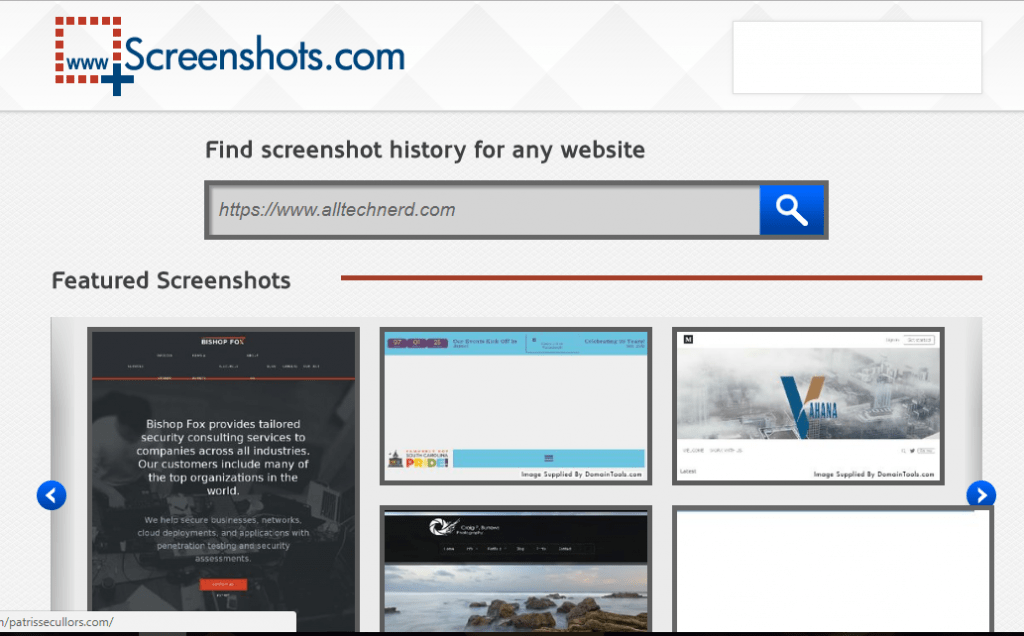
As its name suggests, ScreenShots takes snapshots of websites and saves them to their database. All the details that you are looking for on a particular domain are provided in the snapshot. The code and destination links, among other things, are inaccessible. It has an excellent interface, allowing you to zoom in and focus on the details correctly.
- Uses DomainTools API
- Links the thumbnails’ links to Whois Lookup
- Gives detailed results
2. Archive.is
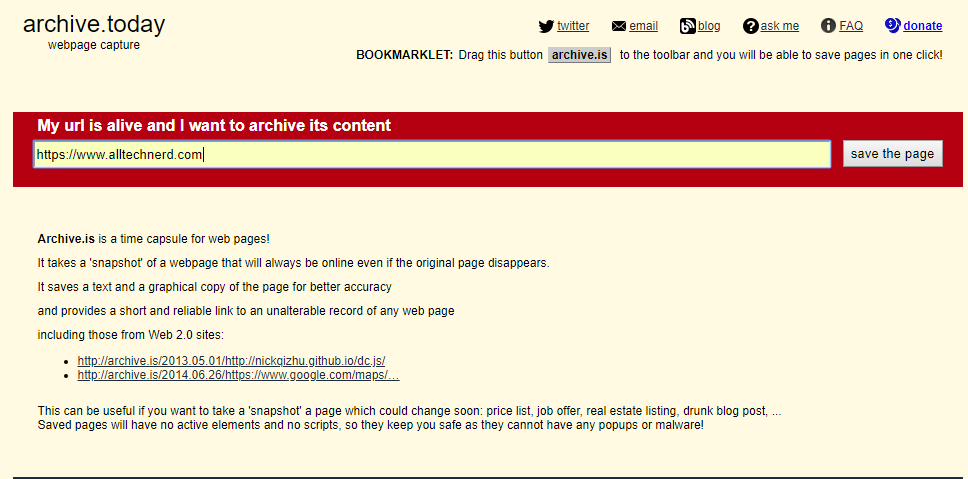
This is arguably the best alternative to the Wayback Machine. What sets it apart from others is that it allows you to access the content and the screenshots of any webpage.
Archive.is famous for its easy and user-friendly navigation. It also has the option to share the screenshots. On top of that, if you need the information for reference later, you can download the report.
- Suitable for crawling images off a domain.
- The original HTML can be downloaded.
- Both screenshots and web pages.
3. Itools
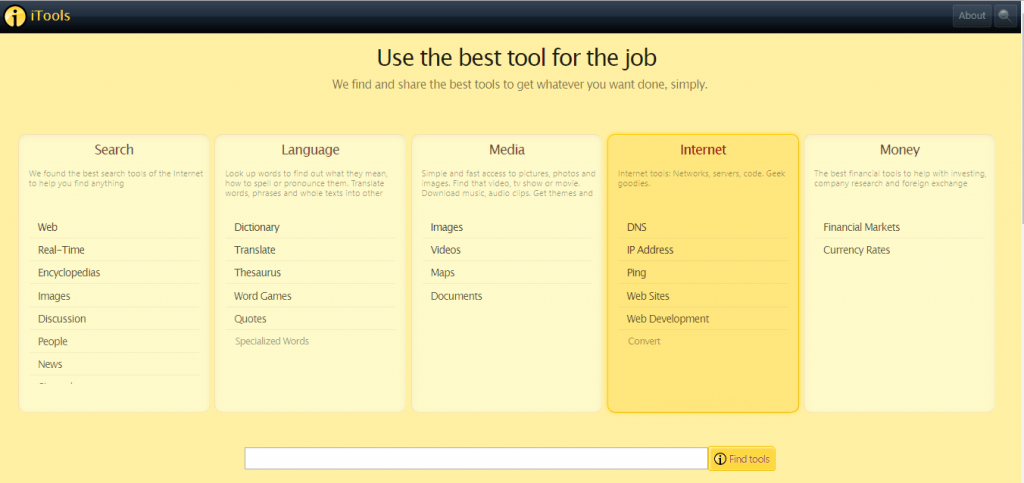
Itools is slightly different from the others on this list because you cannot access the archives from its homepage. You must click on the “Internet” tab, then on “Website”.
Just like the Wayback machine, this uses the Alexa database. It can be an important tool in learning about your competition as it tells a domain’s popularity and traffic.
- Used to boost businesses
- Shows all relevant information on a domain.
4. Competitor screenshots
With the free sign-up, you can compare email campaigns, social media activity, and screenshots.
- Compares and tracks your competition.
- Free sign-up to access basic data.
- Detailed information.
5.WebCite archive
WebCite archive allows you to archive a single URL instantly with WebCite®, You can archive a stable version of a Web page (including Blogs, Wiki, PDF and other documents).
This site archives all the web page data, including any images and media. If the website is already saved in the database, it creates a link to the archived copy. After the process, the confirmation email and archive details will be sent to you.
Technically, this second group does not qualify as an alternative to the Wayback Machine. After configuring it to start tracking your website, it only allows you to look into the past. For specific usage, this is a better alternative to the Wayback machine as it gives you complete control. It’s used to keep track of a competitor’s domain. You never have to worry about take-down requests. Though these are paid.
This Group includes:
6.PageFreezer

PageFreezer is a SaaS-based service maintained by PageFreezer Software, Inc. in Canada. This SaaS-Based Service lets you create your website a web archive file and for the blog and social media. It automatically collects your data without doing any manual work or scheduling time to collect it yourself. They store data on their servers, which is capable of long-term storage.
7.Actiance

Actiance is the leader in communications compliance, archiving, and analytics. Banks use their services, too. It creates your website’s web archive file efficiently.
These are some of the best Wayback machine alternatives we came up with. Let us know in the comment section if you have any other suggestions.






{kind=link}